by Ashis Pati
Moving Towards Automatic Music Performance Assessment Systems
Improving one’s proficiency in performing a musical instrument often requires constructive feedback from a trained teacher regarding various aspects of a performance, e.g., its musicality, note accuracy, rhythmic accuracy, which are often hard to define and evaluate. While the positive effects of a good teacher on the learning process is unquestionable, it is not always practical to have a teacher during practice. This begs the questions if we can design an autonomous system which can analyze a music performance and provide the necessary feedback to the student. Such a system will allow students without access to human teachers to learn music, effectively enabling them to get most out of their practice sessions.
What are the limitations of the current systems?
Most of the previous attempts (including our own) at automatic music performance systems have relied on:
- Extracting standard audio features (e.g. Spectral Flux, Spectral Centroid, etc.) which may not contain relevant information pertaining to a musical performance
- Designing hand-crafted features from music which are based on our (limited?) understanding of music performances and their perception.
Considering these limitations, relying on standard and hand-crafted features for the music performance assessment tasks leads to sub-optimal results. Instead, feature learning techniques which have no “prejudice” and can learn relevant features from the data have shown promise at this task.
Deep Neural Networks (DNNs) form a special class of feature learning tools which are capable of learning complex relationships and functions from data. Over the last decade or so, they have emerged as the architecture-of-choice for a large number of discriminative tasks across multiple domains such as images, speech and music. Thus, in this study, we explore the possibility of using DNNs for assessing student music performances. Specifically, we evaluate their performance with different input representations and network architectures.
Input Representations and Network Architectures
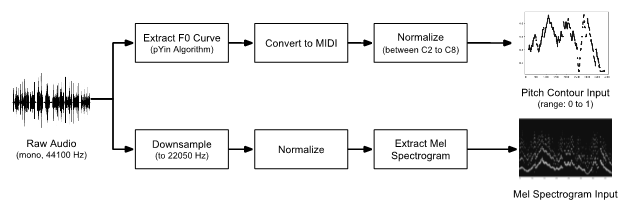
We chose input representations at two different levels of abstraction: a) Pitch Contour which extracts high level melodic information, and b) Mel-Spectrogram which extracts low-level information across several dimensions such as pitch, amplitude and timbre. The flow diagram for the computation of the input representations is shown in the Figure below:
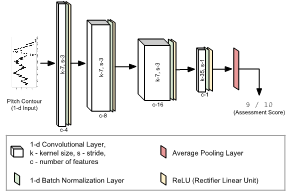
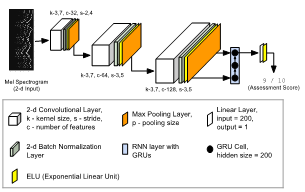
Three different model architectures were used: a) A fully convolutional model with Pitch Contour as input (PC-FCN), b) A convolutional recurrent model with Mel-Spectrogram at input, and (M-CRNN) c) A hybrid model combining information both the input representations (PCM-CRNN). The three model architectures are shown below.
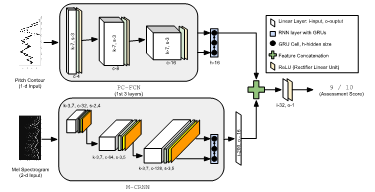
Experiments and Results
For data, we use the student performance recordings obtained from the Florida All-State auditions. Each performance is rated by experts along 4 different criteria: a) Musicality, b) Note Accuracy, c) Rhythmic Accuracy, and d) Tone Quality. Moreover, we consider two categories of students at different proficiency levels: a) Symphonic Band and, b) Middle School and design separate experiments for each category. Three instruments are considered: Alto Saxophone, Bb Clarinet and Flute.
The models are trained to predict the ratings (which are normalized between 0 and 1) given by the experts. As baseline, we use a Support Vector Regression based model (SVR-BD) which relies on standard and hand-crafted features extracted from the audio signal. More details about the baseline model can be found in our previous blog post. The performance of the models at this regression task is summarized as the plot in Figure 6. The coefficient of determination (R2) is used as the evaluation metric (higher is better).
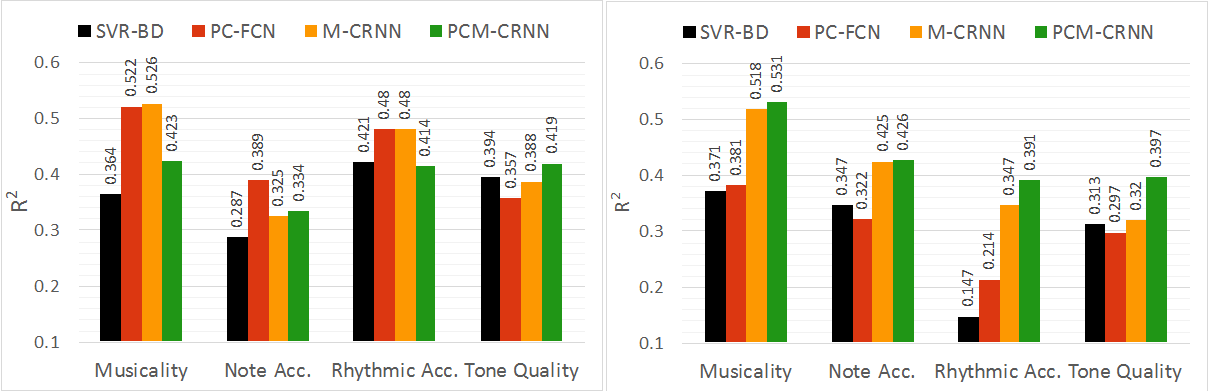
The results clearly show that the DNN based models outperform the baseline model across all 4 assessment criteria. In fact, the DNN models perform the best for the Musicality criterion which is arguably the most abstract and is hard to define. In the absence of a clear definition, it is indeed difficult to design features to describe musicality. The success of the DNN models at modeling this criterion is, thus, extremely encouraging.
Another interesting observation is that the pitch contour based model (PC-FCN) outperforms every other model for the Symphonic Band students. This could indicate that the high-level melodic information encoded by the pitch contour is important to assess students at a higher proficiency level since one would expect that the differences between individual students would be finer. The same is not true for Middle School students where the best models use the Mel-Spectrogram as the input.
Way Forward
While the success of DNNs at this task is encouraging, it should be noted, however, that the performance of the models is still not robust enough for practical applications. Some of the possible areas for future research include experimenting with other input representations (potentially raw audio), adding musical score information as input to the models and training instrument specific models. It is also important to develop better model analysis techniques which can allow us to understand and interpret the features learned by the model.
For interested readers, the full paper published in the Applied Sciences Journal can be found here.