by Chih-Wei Wu
Data availability is the key to the success of many machine learning based Music Information Retrieval (MIR) systems. While there are different potential solutions to deal with insufficient data (for instance., semi-supervised learning, data augmentation, unsupervised learning, self-taught learning), the most direct way of tackling this problem is to create more annotated datasets.
Automatic Drum Transcription (ADT) is, similar to most of the MIR tasks, in need of more realistic and diverse datasets. However, the creation process of such datasets is usually difficult for the following reasons: 1) the synchronization between the drum strokes the onset times has to be exact. In previous work, this was done by installing triggers on the drum sets. However, the installation and the recording process also limits the size of the dataset. Another work around solution is to synthesize drum tracks with user defined onset time and drum samples; this will result in drum tracks with perfect ground truth, but the resulting music might be unrealistic and unrepresentative of the real-world music. 2) the variety of the drum sounds has to be high enough to cover a wide range from electronic to acoustic drum sounds. Most of the previous work only uses a small subset of drum sounds (e.g., certain drum machines or a few drum kits), which is not ideal in this regard. 3) the playing techniques can be hard to differentiate, especially on instruments such as snare drum. A majority of existing datasets only contain the annotations of the basic strikes for simplicity.
We try to address the above mentioned difficulties by introducing a new ADT dataset with a semi-automatic creation process.
Why MDB?
The goal of this project is to create a new dataset with minimum effort from the human annotators. In order to achieve this goal, a robust onset detection algorithm to locate the drum events is important. To ensure the robustness of the onset detector, we want the input signal to be as clean as possible. However, we also want to have a signal to be as realistic as possible (i.e., polyphonic mixtures of both melodic and percussive instruments). With these considerations in mind, we decided to avoid collecting a new dataset from scratch but rather work on the existing dataset with desirable properties.
As a result, the MusicDelta subset in the MedleyDB dataset is chosen for its:
- Multitrack format. This can potentially increase the robustness of onset detector and facilitate the semi-automatic annotation process. In addition, the multitrack files can be mixed in any arbitrary combination, providing more possibilities for experimentation.
- Real-world recordings. This means the recordings are more realistic and closer to the real use cases. Also, the diversity in terms of music genres offers a more representative sample pool.
Dataset creation
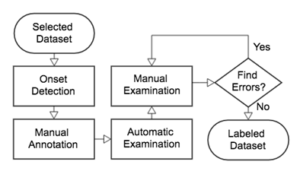
The processing flow of the creation of MDB Drum is shown in Fig. 1. First, the songs in the selected dataset are processed with an onset detector. This provides a consistent estimation of the onset locations. Next, the onsets are labeled with their corresponding instrument names (i.e., Hi-hat, Snare Drum, Kick Drum). This step inevitably requires manual annotation from the human experts. Following the manual annotation, a set of automatic checks were implemented to examine the annotations for common errors (e.g., typos, duplicates). Finally, the human experts went through an iterative process of cross-checking their annotations prior to the release of the dataset.
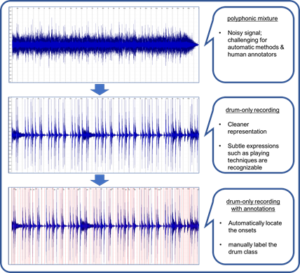
An dataset example is shown in Fig. 2. The original polyphonic mixture (top) appears noisy, and it is difficult to locate the drum events through both listening and visual inspection. The drum-only recording (middle), however, has sharp attacks and short decays in the waveform, providing a cleaner representation for the onset detector. Finally, the detected onsets (bottom), as marked in red, are relatively accurate, which greatly simplifies the process of manual annotation.
Dataset
The resulting dataset contains 23 tracks of real-world music with a diverse distribution of music genres (e.g., rock, disco, grunge, punk, reggae, jazz, funk, latin, country, britpop, to name just a few). The average duration of the tracks is around 54s, and the number of annotated instrument classes is 6 (only major classes) or 21 (with playing techniques). The users may choose to mix the multitracks in any combination (e.g., guitar + drum, bass + drum) due to the multitrack format of the original MedleyDB dataset.
All details can be found in our short paper here.