by Chih-Wei Wu
Building a computer system that “listens” and “understands” music is the goal of many researchers working in the field of Music Information Retrieval (MIR). To achieve this objective, identifying effective ways of translating human domain knowledge into computer language is the key. Machine learning (ML) promises to provide methods to fulfill this goal. In short, ML algorithms are capable of making decisions (or predictions) in a way that is similar to human experts; this is achievable by browsing and observing patterns within so called “training data.” When large amounts of data are available (e.g., images and text), modern ML systems can perform comparably or even outperform human experts in tasks such as object recognition in images.
Similarly, to train a successful ML model for MIR tasks, (openly available) data also plays an essential role. Useful training data usually includes both the raw data (e.g., audio files, video files) and annotations that describe the answer for a certain task (such as the music genre, the tempo of the music). With a reasonable amount of data and correct ground truth labels, the ML models may build a function that maps the raw data to their corresponding answers.
One of the first questions new researchers ask is: “How much data is needed to build a good model?” The short answer to the first question is the more the better. This answer may be a little unsatisfying, but it is often true for ML algorithms (especially the increasingly popular deep neural networks!). The human annotation of data, however, is labor-intensive and does not scale well. This situation gets worse when the target task requires highly skilled annotators and crowdsourcing is not an option. Automatic Drum Transcription (ADT), a process that extracts the drum events from the audio signals, is a good example of such skill demanding task. To date, most of the existing ADT datasets are either too small or too simple (synthetic).
To find a potential solution for this problem, we try to explore the possibility of having ML systems learn from the data without labels (as shown in Fig. 1).
Unlabeled data has the following advantages: 1) it is easily available compared to labeled data, 2) it is diverse, and 3) it is realistic.
We explore a fascinating way of using unlabeled data referred to as the “student-teacher” learning paradigm. In a way, it uses “machines to teach machines.” As researchers have been working on systems for drum transcription before, these existing systems can be utilized as teachers. Multiple teachers “transfer” their knowledge to the student and the unlabeled data is used as the medium to carry the knowledge of the teachers. The teachers make their predictions on the unlabeled data and the student will try to mimic the teachers’ predictions and become better and better at certain task. Of course, the teachers might be wrong, but the assumption is that multiple teachers and a large amount of data will compensate for this.
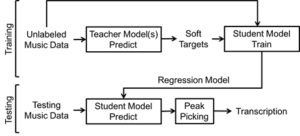
Figure 2 shows the presented system consisting of a training phase and a testing phase. During the training phase, all teacher models will be used to generate their predictions on the unlabeled data. These predictions will become “soft targets” or pseudo ground truth. Next, the student model is trained on the same unlabeled data with the soft targets. In the testing phase, the trained student model will be tested against an existing labeled dataset for evaluation.
The exciting (preliminary) result of this research is that the student model is actually able to outperform the teachers! Through our evaluation, we show that it is possible to get a student model that outperforms the teacher models on certain drum instruments for ADT task. This finding is encouraging and shows the potential benefits we can get from working with unlabeled data.
For more information, please refer to our full paper. The unlabeled dataset can be found on github.